

Domain Histories: Cloud Infra & Compute
The best founders are students of history

This is Domain Histories — a weekly series mapping startup domains from first principles. The best founders are students of history. Patrick Collison met Visa's founder before building Stripe. Apoorva Mehta studied Webvan's collapse before building Instacart. They used history to make specific decisions about what to build, what to avoid, and when to move. Each issue takes one domain and gives you the full map: who tried before, why they failed, where the money sits, what's shipping now, and what a founder entering today should do differently because of it. Not a market overview. Not a research report. The history that changes what you build.

The cloud promised infinite scale. It delivered infinite invoices.
Every founder gets the pitch: elastic compute, pay-as-you-grow, infrastructure as code. Then they ship to production and discover they’re paying $47,000 a month to serve three thousand users. The cloud didn’t lie — you just didn’t know the game had changed three times since you learned the rules.
Here’s what actually happened: Amazon built AWS to monetise spare capacity in 2006. By 2015, “cloud-first” was doctrine. By 2020, CFOs were asking why the bill kept growing faster than revenue. Now? AI workloads are rewriting the entire economics again, and the hyperscalers are spending $125 billion a year to make sure you have no choice but to rent from them.
The founders who win understand this isn’t about technology. It’s about where value pools, who controls the choke points, and why the companies that tried to compete on infrastructure alone are now case studies in expensive lessons.
The Original Problem
Before 2006, if you wanted to launch a web application, you bought servers. Plural. Upfront. You guessed at capacity, over-provisioned to avoid downtime, and paid for idle metal. Scaling meant procurement cycles, data centre contracts, and hiring ops teams. The capital requirement killed most ideas before they launched.
The problem wasn’t just money — it was time. Provisioning infrastructure took weeks. If you got it wrong, you either ran out of capacity during a traffic spike or paid for servers gathering dust. Every startup needed to solve the same infrastructure problems before they could solve their actual problem.
Amazon had a different issue: massive seasonal variance in retail traffic. They built infrastructure for Christmas, then watched it sit idle in February. The insight wasn’t “let’s build a cloud” — it was “we’ve already solved this, and everyone else is still buying servers.”
The Numbers
The Timeline
Era 1: The Utility (2006-2010)
What enabled it: Amazon’s excess capacity + web 2.0 boom + open-source stack maturity
AWS launched S3 and EC2 in 2006, offering compute by the hour. No contracts, no minimum spend, pay with a credit card. This democratised infrastructure, allowing startups like Airbnb and Spotify to launch without millions in upfront capital. The playbook was simple: provision EC2 instances, deploy your code, scale horizontally.
Why it ended: The market matured. Access to infrastructure stopped being a differentiator. The advantage shifted from “can you get infrastructure” to “can you manage it efficiently.”
What it means now: If your startup’s competitive advantage is “we’re cloud-native,” you’re a decade late. That’s table stakes.
Era 2: The Migration (2011-2018)
What enabled it: Enterprise IT budget shifts + Microsoft’s Azure bet + “digital transformation” consulting boom
Hyperscalers targeted enterprises. Microsoft launched Azure in 2010, leveraging its existing Windows Server customer base. Google Cloud followed in 2011. The offerings expanded beyond raw compute to managed services like databases and identity management. This era saw a boom in cloud consulting, with firms charging millions for “lift-and-shift” migrations where on-prem VMs were simply moved to the cloud.
Why it ended: Most enterprises that could migrate had done so. Growth rates in pure migration slowed. CFOs began questioning escalating cloud bills without corresponding revenue growth. The easy wins were gone.
What it means now: The “cloud migration” wave is over. If you’re building migration tools, you’re selling to laggards. Value now comes from optimisation within existing cloud deployments.
Era 3: The Reckoning (2019-2023)
What enabled it: Cloud maturity + cost optimisation pressure + multi-cloud complexity
Companies faced unexpectedly high and rapidly growing cloud bills. This led to the rise of FinOps, a discipline focused on managing cloud spending. Startups like Vantage and CloudZero emerged to help decipher complex invoices. The “cloud-first” mantra became “cloud-smart,” emphasising efficiency and value. Some companies even repatriated workloads from the cloud to cut costs. Multi-cloud strategies, driven by a desire for negotiating leverage rather than just redundancy, became common.
Why it ended: AI happened. The demand for specialised, high-performance compute (especially GPUs) overshadowed previous cost concerns and shifted focus from economising general workloads to acquiring new, bottlenecked resources.
What it means now: Cost optimisation remains critical, but the game is fundamentally altered by AI workloads, which have vastly different economic profiles.
Era 4: The AI Infrastructure Boom (2024-Present)
What enabled it: Large language models + GPU scarcity + enterprise AI adoption
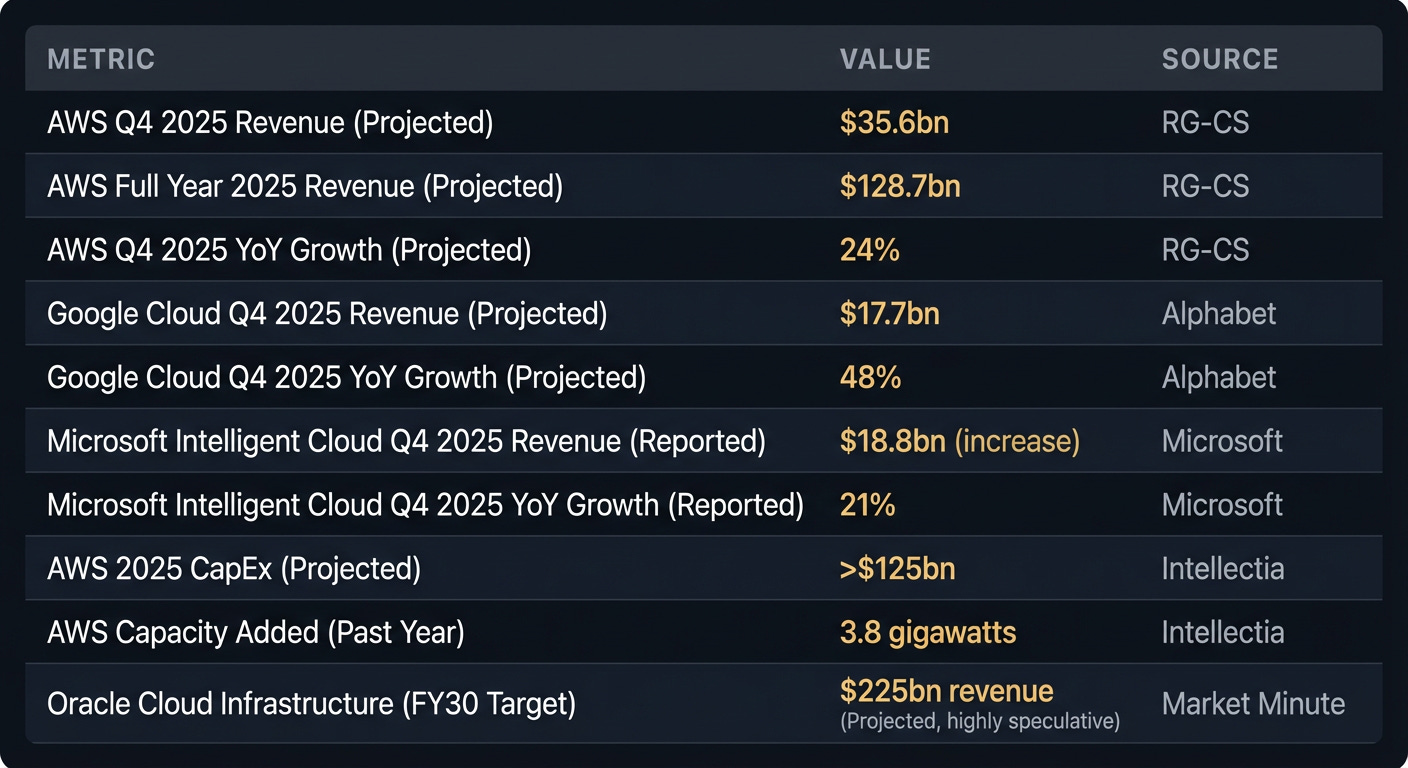
This era is characterised by a surge in demand for AI-specific infrastructure. AWS, Google Cloud, and Microsoft Intelligent Cloud are all reporting significant growth, driven by AI workloads like model training, inference, and fine-tuning. The hyperscalers are investing unprecedented capital into this space; AWS alone projects over $125 billion in CapEx for 2025. This isn’t about general compute anymore – it’s about GPUs, TPUs, custom silicon like Azure Cobalt, and the high-speed networking needed to connect them.
The playbook: Hyperscalers build proprietary AI infrastructure, then lock in customers with tailored tooling and services, making switching prohibitively expensive.
What it means now: If your application relies on training and high-scale inference with advanced models, you’ll likely rent from a hyperscaler for the foreseeable future. The challenge is navigating rapidly increasing demand and pricing, and securing access to scarce resources.
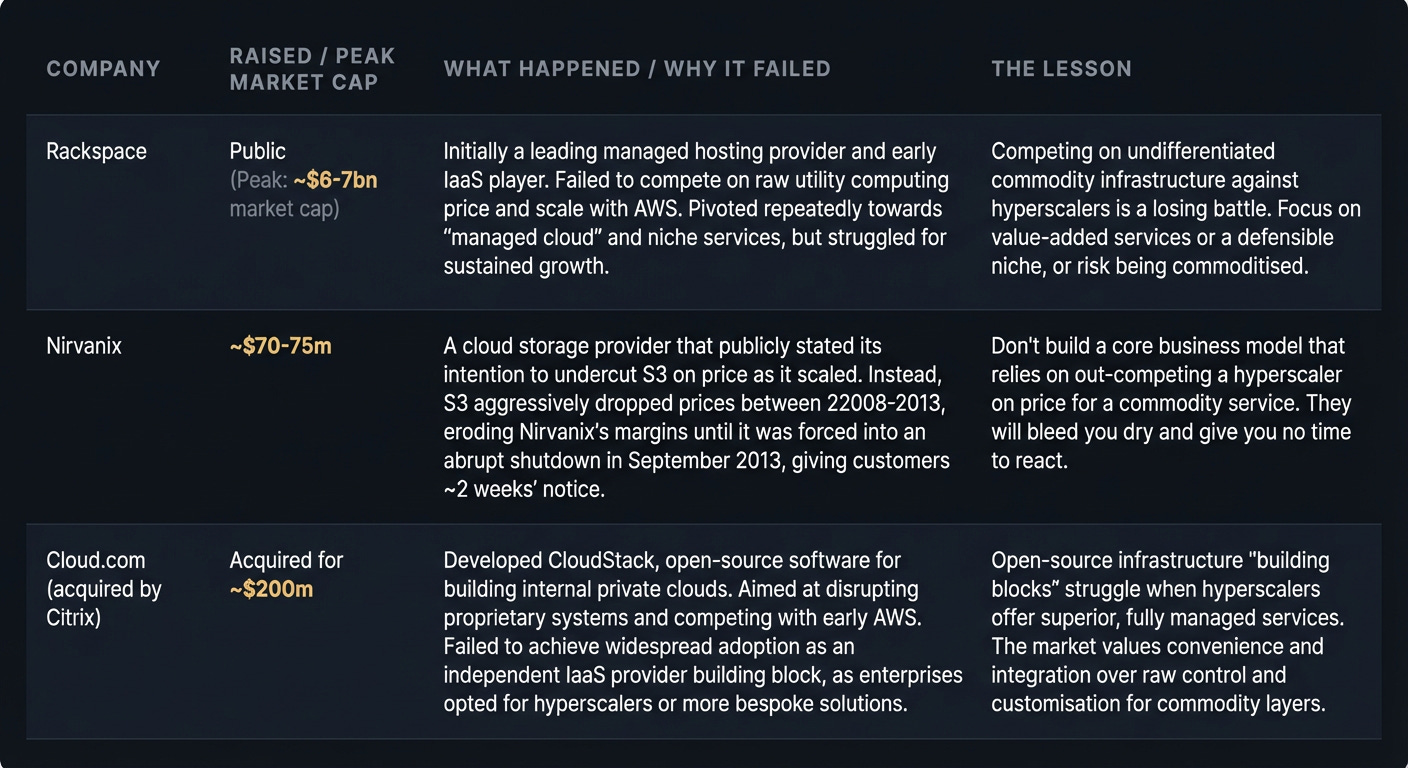
The Graveyard
Where The Money Sits
The value chain:
Physical infrastructure (data centres, power, cooling)
Virtualisation layer (hypervisors, orchestration)
Managed services (databases, queues, caching)
Developer tools (deployment, monitoring, security)
Application layer (your product)
Who owns what: AWS, Google Cloud, and Microsoft Azure completely control layers 1-3 and increasingly dominate layer 4. They are vertically integrated from custom silicon (AWS Graviton, Google TPU, Azure Cobalt) to the API.
The blind spots:
Cost visibility: Hyperscalers make it deliberately hard to predict your bill. Pricing pages are labyrinthine for a reason.
Egress fees: Data transfer out costs 10-20x more than transfer in. This is the hidden tax, designed to discourage you from leaving.
AI compute allocation: GPUs are rationed. If you aren’t spending millions monthly, be prepared for queues and limited access.
The tax everyone pays: Egress fees. Moving data between regions, between clouds, or out to users is priced to create friction and discourage portability.
What’s Actually Hard
Predicting your bill before you ship. A common trap: a prominent SaaS startup estimated $5k/month for dev usage, but their production bill hit $47k in month two. The difference came from idle resources, snapshot storage, and logs – all cost money even with low traffic. The lesson from Nirvanix applies here: don’t assume your cost model will hold against the hyperscalers’ scale and predatory pricing.
Avoiding vendor lock-in while moving fast. Every managed service (e.g., DynamoDB, Azure Functions, GCP BigQuery) is a lock-in decision. The trade-off is speed vs. operational overhead of running open-source alternatives. Most founders opt for speed, then face migration pain when the bills get too high.
Securing GPU capacity on demand. If you’re not a hyperscaler’s strategic customer, you’ll be waiting. Building an AI product only to find you can’t get the compute to train or serve models at scale is a common, painful discovery. This scarcity drives up costs and delays launches.
Understanding “serverless” costs beyond the obvious. Lambda pricing looks cheap per invocation, but cold starts can ruin performance, and the aggregate cost for millions of small calls, coupled with logging and network costs, often becomes higher than expected. Teams often end up provisioning dedicated capacity anyway, negating the “serverless” benefit.
Hiring engineers who understand cost implications. Junior engineers provision resources like they’re free. Senior engineers who’ve been on-call for a $200k/month cloud bill make very different decisions. This experience gap is a constant drain on budgets.

What’s Shipping Now
AWS Doubles Down on AI Infrastructure: Amazon isn’t just adding more servers; they’re aggressively expanding their AI-specific computing capacity. AWS added 3.8 gigawatts in the past year and plans to double it by 2027, sinking over $125 billion in CapEx for 2025 alone. What this means for founders: Don’t expect a sudden flood of cheap, easy-to-access GPUs. Despite massive investment, demand continues to outstrip supply, pushing up costs and making resource allocation a strategic bottleneck. Plan for constrained compute access.
Google Cloud Targets Enterprise AI: Google Cloud is projecting a massive 48% growth in Q4 2025, heavily driven by enterprise AI infrastructure and tailored solutions. They’re positioning themselves as the go-to for large businesses adopting AI. What this means for founders: If your startup builds B2B AI tools, Google Cloud’s ecosystem offers prime integration opportunities and a clear path to enterprise customers who prioritize integrated tooling and managed services over raw infrastructure.
Oracle Enters the AI Ring with $50 Billion Bet: Oracle is funding gigantic AI data centres, aiming for a projected $225 billion revenue by 2030 in this space. They’re building an alternative for enterprises wary of hyperscaler dominance. What this means for founders: Oracle’s aggressive expansion could introduce a new competitive dynamic, potentially offering more niche-specific or cost-effective options for certain highly regulated enterprise AI workloads. Keep an eye on their specialized offerings for potential partnerships or deployments.
Microsoft Azure’s AI Dominance Strengthens: Microsoft’s Intelligent Cloud saw 21% YoY growth in FY25 Q4, with Azure services growing 34% driven significantly by AI. With strong enterprise ties and investments in custom AI silicon like Azure Cobalt, Microsoft is cementing its role. What this means for founders: Azure remains a critical platform for B2B AI solutions, especially for companies already embedded in the Microsoft ecosystem. Their integrated tooling and enterprise reach offer significant advantages for go-to-market and customer acquisition.
IBM’s Hybrid AI Play for the Enterprise: IBM reported strong double-digit growth in Software and Infrastructure in Q4 2025, fueled by watsonx AI and hybrid cloud solutions. They’re focusing on enterprises with strict compliance needs or existing on-prem infrastructure. What this means for founders: If your AI solution requires maximum data sovereignty, operates in a highly regulated industry, or integrates with legacy systems, IBM offers a mature hybrid cloud path. This avoids cloud sprawl and provides a clearer, compliant route to AI adoption where public cloud may be unsuitable.
Where This Goes
This isn’t about predictions. It’s about making deliberate bets on a changing landscape.
GPU supply will stay lumpy: Design for burst/queueing. Don’t assume infinite, on-demand capacity for large models. Your architecture should accommodate periods of constrained compute.
Hybrid is back, particularly for AI: Ship on-prem-friendly deploys early. Assume some enterprise AI workloads will move to private cloud or local infrastructure for cost, data sovereignty, or compliance.
FinOps becomes control loops, not just dashboards: Translate cost awareness into automated enforcement. The money is in preventing runaway spend with guardrails, not just reporting it reactively.
The hyperscalers will maintain dominance, but the significant margin now sits in managed AI services on top of raw compute. Startups building on these services—offering better cost controls, improved developer experience, or specialised compliance tooling—can capture value without competing on infrastructure head-on.
Moves Worth Stealing
Amazon’s capacity announcement strategy: AWS doesn’t just add capacity; they announce it quarters in advance to signal stability and invite commitment. This is forward guidance for infrastructure. Founders take note: If you’re building a capital-intensive product, telegraph your roadmap early and clearly. Reduce customer uncertainty by showing them your long-term investment.
Oracle’s late-entrant positioning: Oracle explicitly targets enterprises seeking AI infrastructure alternative to AWS. They don’t compete on breadth, but on “we’re not Amazon,” appealing to companies wary of hyperscaler dominance. Founders take note: If you’re entering a market with entrenched players, identify existing customer dissatisfaction (e.g., vendor lock-in, lack of specific features) and position yourself as the strategic alternative.
IBM’s hybrid play: IBM isn’t fighting the public cloud migration battle; they’re serving enterprises that recognize the limitations of cloud-only for certain workloads. They offer hybrid cloud contracts that bundle on-prem software licenses with public cloud consumption. Founders take note: If the market has swung heavily in one direction, look for underserved segments moving against that trend. There’s often value in serving the counter-narrative, especially in highly regulated or cost-sensitive industries.
Microsoft Azure’s ecosystem lock-in: Azure leverages tightly integrated AI offerings within its massive enterprise ecosystem (Microsoft 365, development tools). This creates a sticky environment where users benefit from seamless workflows, making switching costly even if raw compute might appear cheaper elsewhere. Founders take note: If you have an established user base or complementary products, integrate your new offering deeply to create network effects and significant switching costs. Focus on experience, not just feature parity.
The Why Now
The timing signal: AI workloads are fundamentally different. They are more compute-intensive, expensive, and less predictable than traditional web applications. This is creating a new set of problems the hyperscalers are still figuring out. There’s a 12-18 month window where the economic models are in flux.
What’s different: For the first time since 2010, there’s genuine scarcity in cloud compute, specifically GPUs. This isn’t a problem of scaling up general capacity; it’s a bottleneck in a critical, specialised resource. This scarcity creates immense opportunity for solutions that tackle allocation, optimisation, and alternative architectures.
The window: Hyperscalers will eventually solve the GPU capacity problem. But right now, they are supply-constrained, and this constraint is creating an urgent need for tools, platforms, and services that help companies maximize what they can get, or find viable alternatives. This window will close as capacity catches up.
If You’re Starting Monday
The wedge: Don’t compete on raw infrastructure. Build on top. The most impactful cloud startups of this era will be FinOps platforms for AI, intelligent workload orchestration layers, or specialised compliance automation tools for AI deployments. Find a specific, acute pain point that emerges at significant scale and build your wedge there.
The trap: The allure of building yet another “cloud abstraction layer” for portability, like Cloud.com attempted. Every abstraction layer you build to avoid vendor lock-in is engineering effort you’re not putting into your core product. Pick your lock-in consciously, optimise it ruthlessly, and build value elsewhere.
The customer: Mid-market companies with serious AI ambitions but without hyperscaler-level budgets or dedicated FinOps teams. They’re trying to figure out why their $50k/month GPU capacity quote is so high and how to make it sustainable. Serve them first, learn their pain, then aim for the deep enterprise.
The first hire: Someone who has personally managed a six-figure monthly cloud bill for an AI or high-scale workload. Not a generalist DevOps engineer, but someone who has been in the war room, justifying a 300% cloud bill spike to a board and solving it. That specific, battle-tested experience is invaluable.
This week:
Set granular cost budgets and alerts for all cloud services, especially AI-related ones.
Pick one managed service you rely on and document its exact exit plan (i.e., what would it take to migrate off it).
Proactively secure GPU capacity via reservations, partnerships, or by designing architectural fallbacks for peak loads.
Go Deeper
RG-CS - Massive AWS Cloud Growth Late 2025: Projections for AWS’s accelerated growth driven by AI. [RG-CS]
Alphabet Q4 2025 Earnings: Google Cloud’s strong growth figures, particularly in enterprise AI. [Alphabet]
Microsoft FY25 Q4 Intelligent Cloud Performance: Azure’s contribution to Microsoft’s growth, highlighting AI impact. [Microsoft]
Intellectia - Amazon’s E-commerce Profitability Shift: Context on Amazon’s massive Capex, capacity additions, and future plans. [Intellectia]
Market Minute - Oracle’s Valuation Reset: Oracle’s aggressive move into AI infrastructure with substantial investment. [Market Minute]
IBM Newsroom - Q4 2025 Results: IBM’s strong performance driven by watsonx AI and hybrid cloud. [IBM Newsroom]
For the ❤️ of startups

Arthur is the AI native startup operating system I’m building in public — not hype, but a system that turns input into structured execution and tracks founder progress. If you want to follow or use it, it’s open for early access.
→ Access Arthur
Thank you for reading. If you liked it, share it with your friends, colleagues and everyone interested in the startup Investor ecosystem.
If you’ve got suggestions, an article, research, your tech stack, or a job listing you want featured, just let me know! I’m keen to include it in the upcoming edition.
Please let me know what you think of it, love a feedback loop 🙏🏼
🛑 Get a different job.
Subscribe and follow me on LinkedIn or Twitter to never miss an update.